LayerFlow
LayerFlow: A Unified Model for Layer-aware Video Generation
Abstract
本文提出了 LayerFlow,一个能够感知图层的视频生成解决方案。根据每层的文本提示,LayerFlow 可以生成透明前景、清晰背景和混合场景的视频。它还支持多种变体,例如分解混合视频或为给定的前景生成背景,反之亦然。从文本到视频的扩散变换器开始,本文将不同层的视频组织为子片段,并利用层嵌入来区分每个片段和相应的图层提示。通过这种方式,在一个统一的框架中无缝地支持上述变体。由于缺乏高质量的图层训练视频,设计了一种多阶段训练策略,以适应具有高质量图层注释的静态图像。具体来说,首先使用低质量视频数据训练模型。然后,调整运动 LoRA,使模型与静态帧兼容。之后,利用混合了高质量分层图像和复制粘贴视频数据的 LoRA 内容进行训练。在推理过程中,去除了 LoRA 的运动部分,从而生成具有所需层次的流畅视频
Introduction
本文工作的主要贡献如下:
LayerFlow 在生成质量和语义对齐方面展现出远超其他解决方案(例如仅基于视频进行训练或生成后再进行动画制作的解决方案)的出色能力。此外,通过去除指定视频片段中的噪声,可以对该片段进行条件化处理以生成剩余片段,从而在统一框架中实现图 1 中的多个衍生应用。例如,背景条件生成会在输入视频上绘制前景,反之亦然;而多层分解则会从给定视频中减去独立的视频层。LayerFlow 展现出作为分层视频创作基础解决方案的潜力,它能够通过多模态条件为更多奇特的应用赋能。
Method
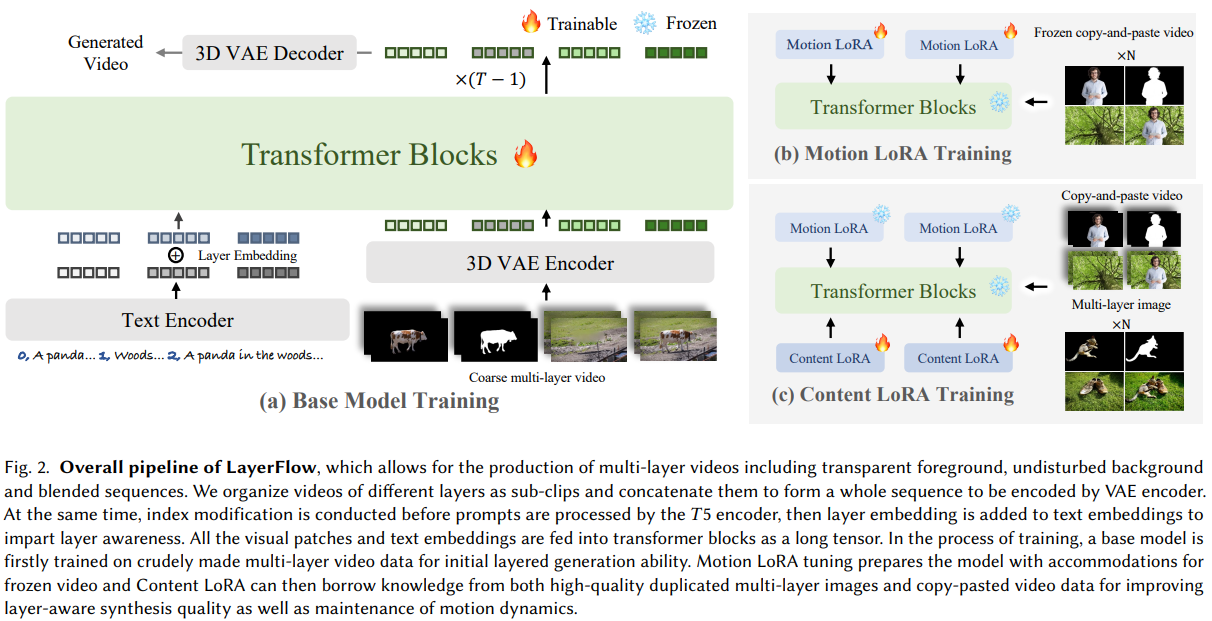
LayerFlow的Pipeline如figure 2所示,分别地给定对于不同目标层级的三个文本输入,LayerFlow能够生成高保真的、以及与每层文本提示对齐的前景,alpha通道,背景以及融合的视频。在本部分的方法详述中,首先阐述整体框架,然后介绍构建在训练策略以及数据集贡献训练管线。
Overall Framework
本文首先通过将所有层的子片段连接成一个整体以将基于 DiT 的 T2V 模型适配到层感知生成场景;然后通过在逐层文本嵌入上插入层嵌入,将每层的视觉内容与相应的文本提示对齐。 基于两个精心设计的 LoRA ,可以采用多阶段方案对模型进行微调,这将在 3.2 节关于联合图像-视频数据的说明中详细介绍,以合成高质量的视频。还可以基于这样一个统一的框架实现条件分层视频生成,以支持多种变体。
Layer-wise video representation。提出了一种简单有效的公式来表示视频中的不同层,将包括 alpha-matte 在内的各层的视觉嵌入连接成一个长序列。接下来的 3D 注意力机制将文本和视频关联起来,并在各层之间共享信息,从而增强层间一致性。需要注意的是,将前景分为 RGB 序列和 alpha 序列以表示透明度,因此可以将其组合为“RGBA 视频”以供进一步重组。
Layer-wise text prompts。为了使生成的视频片段分别指向相应的提示,建议对文本输入和编码嵌入进行文本修改,以赋予层感知能力。具体而言,在用 T5 编码的每个层的描述之前,以“索引号,层描述”的格式将索引号附加到提示中。编码后,可学习的层嵌入器将索引号投影到与文本嵌入大小相同的层嵌入,然后再添加到相应的文本嵌入中。所有上述修改以及位置嵌入,通过显式和隐式地建立文本和视觉嵌入对之间的对应关系,将每个层与其描述联系起来。
Conditional layer generation。还可以对该框架进行一些简单的修改,以支持各种条件层生成变体,包括前景/背景条件生成以及层分解。更具体地说,通过去除视觉嵌入的前景片段中的噪声,并将其从训练过程中的损失计算中分离出来,前景序列将作为剩余视频片段合成的条件,并且仅用于注意力共享,以建模层间关系。因此,该框架成为一个前景条件视频生成器。其他两个应用也进行了类似的修改,将在实验中演示所有这些变化。
Training Pipeline
能够感知层的视频生成模型需要高质量的多层视频,这类视频往往难以获得或者构建。为了解决这个问题,本文提出了一个三阶段的训练策略,结合了静态图像和动态视频数据,利用了运动以及内容LoRA来解决数据稀缺这一问题,能够显著改进视频的内层连贯性,美学质量以及运动动态(inter-layer coherence,aesthetic quality, and motion dynamics)。
第一阶段:基模型训练。本文首先在一个低质量多层视频数据集上进行基模型的训练以赋予视频生成模型初始的层感知生成能力。在 $\mathrm{MSE}$ 损失的驱动下,去噪网络 $\epsilon_{\theta}$ 学习预测噪声:
\[\begin{equation} L(\theta):=\mathrm{E}_{t,x_{0},y,i,\epsilon}\|\epsilon-\epsilon_{\theta}\left(\sqrt{\bar{\alpha}_{t}}x_{0}+\sqrt{1-\bar{\alpha}_{t}}\epsilon,t,\right.\tau_{\theta}(y)+\tau_{l}(i_{l}))\|^{2}, \end{equation}\]其中 $i_{l}$ 表示层索引,因此 $\tau_{l}(i_{l})$ 表示层嵌入(layer embedding)。
为了准备该阶段的训练数据,首先在预测的文本提示的指导下,使用SAM-Track从rawa video中分割出前景的视频序列。然后筛选掉重复的mask序列和无效的前景对象,筛选出的mask序列用于指导视频inpainting模型生成背景视频。最后,利用CogVLM2分别地为每一层的视频进行打标。这样一来,便能够得到本文以及视频输入数据对 $\left { foreground, alpha, background, blended \right } $ 。由于分割模型,inpainting模型的不足,以及raw videos的低质量性,输入视频序列可能会包含运动模糊的帧或者有歧义的前景边缘。因此,第一阶段训练后的基本模型输出与当前最先进的视频生成之间存在如 figure 3 所示的不可忽视的质量差距。

第二阶段:Motion LoRA训练。 提升分层视频生成质量的一个关键思路,是在高质量但静态的多层图像数据上进行训练。为了防止由于直接在由重复图像构成的静态视频上训练而导致运动动态的丢失,提出如 figure 2所示,采用Motion LoRA来使基础模型适应图像数据。以query(𝑄)投影为例,投影后的内部特征 $z$ 变为
\[\begin{equation} Q=W^Qz+MotionLoRA(z)=W^Qz+\alpha\cdot AB^Tz. \end{equation}\]该方法在所有 $W\in \left{W^Q,W^K,W^V \right}$ 上实现,通过将标量 $\alpha$ 调整为1和0,以适应静态与动态之间的运动模式。换句话说,在对重复帧进行优化后,当 $\alpha$ 设置为1时,Motion LoRA能够使模型生成静止视频,从而在第三阶段使模型适应图像数据。
为了更好地与第一阶段在视频数据集上训练的transformer骨干网络的初始特征分布对齐,在训练时是从视频中随机采样静态帧进行复制,而不是直接复制图像数据。另一方面,本阶段所用视频数据的质量应当相当高,因为最终优化得到的Motion LoRA将在最后阶段应用于高质量的图像数据。为同时满足这两个要求,一种可选方法是复制可获得的带有透明度的前景视频抠像数据,并将其粘贴到背景视频上,以自制多层视频数据集。需要说明的是,本阶段的拷贝粘贴视频数据集仅用于Motion LoRA的训练,因此由于随机拼贴带来的不连贯性问题不会影响分层视频生成的质量。
第三阶段:Content LoRA训练。通过Motion LoRA使模型适应联合图像-视频训练后,在前两个阶段的transformer骨干网络的相同模块上引入了Content LoRA,其同样是通过低秩矩阵的乘法实现的:
使用与公式(1)中相同的扩散重建损失来优化Content LoRA,对于拷贝粘贴的视频设置 $\alpha=0$,对于作为静止视频的多层重复图像设置 $\alpha=1$。通过这种方式,模型能够从图像抠图数据中学习到高保真度,同时不会丢失基础模型的运动先验。在完成所有三个阶段的训练后,我们在推理时去除Motion LoRA,仅保留Content LoRA用于精细化,这表明该训练流程有助于减少基础模型遗留的负面影响(如背景填充缺陷、前景边界模糊等),并实现多层视频生成中的透明性、高保真度和层间和谐。
本阶段使用的多层图像数据集主要有两个来源:一是可获取的多层标注数据集,如MULAN (Tudosiu et al. 2024);二是经过图像修复和图像描述后处理的图像抠图数据集。与第一阶段使用的粗糙视频数据集相比,多层图像数据集具有透明的前景和和谐的背景,没有明显的运动模糊或伪影,因此在提升多层生成质量方面起着决定性作用。需要注意的是,本阶段也会以较小比例联合使用拷贝粘贴视频,这对生成的一致性影响较弱,但能有效提升保真度,并防止模型丧失动态特性。
EXPERIMENTS
Implementation Details
Training configurations。本文基于具有2B参数量的 T2V 模型,CogVideoX 训练。在所有三个阶段的训练中,仅使用简单的MSE损失,并采用Adam优化器,基础模型微调的学习率为 $1e^{-4}$,Motion LoRA的学习率为$1e^{-3}$,Content LoRA的学习率为$5e^{-3}$。Motion LoRA和Content LoRA同样被附加在基础模型中可训练的1/6 transformer模块上。模型在8张NVIDIA A800显卡上进行优化,每张显卡的训练批量大小为12;而在推理过程中,采样步数设置为50,classifier-free guidance scale设置为6。
Coarse multi-layer video dataset construction。首先,前景分割所用的提示词列表由Recognize Anything生成,该列表包含了视频中可能出现的前景主体。利用生成的前景掩码,接下来根据所有掩码之间的相似性进行筛选,以避免重复的前景对象。Qwen-VL 进一步用于检查分割序列是否为“真实”前景,从而排除诸如天空、湖泊等通常被视为背景的样本。基于上述步骤,完成了粗糙分层视频数据集的构建。