DreamLight
DreamLight: Towards Harmonious and Consistent Image Relighting

Abstract
本文介绍了一个名为 DreamLight 的通用图像重照明模型。该模型能够将主体无缝地合成到新的背景中,同时在光照和色调方面保持审美上的一致性。其背景既可以通过自然图像来指定(基于图像的重照明),也可以通过无限的文本提示来生成(基于文本的重照明)。DreamLight 将输入数据重组为统一的格式,并利用预训练扩散模型提供的语义先验知识来促进自然结果的生成。此外,DreamLight提出了一种位置引导的光照适配器(Position-Guided Light Adapter, PGLA),它将来自背景不同方向的光照信息凝聚到设计好的光照查询嵌入中,并使用带有方向偏置的掩码注意力机制来调节前景。另外,DreamLight还提出了一个名为频谱前景修复器(Spectral Foreground Fixer, SFF)的后处理模块,用于自适应地重组主体与重照明后背景的不同频率分量,这有助于增强前景外观的一致性。
Method
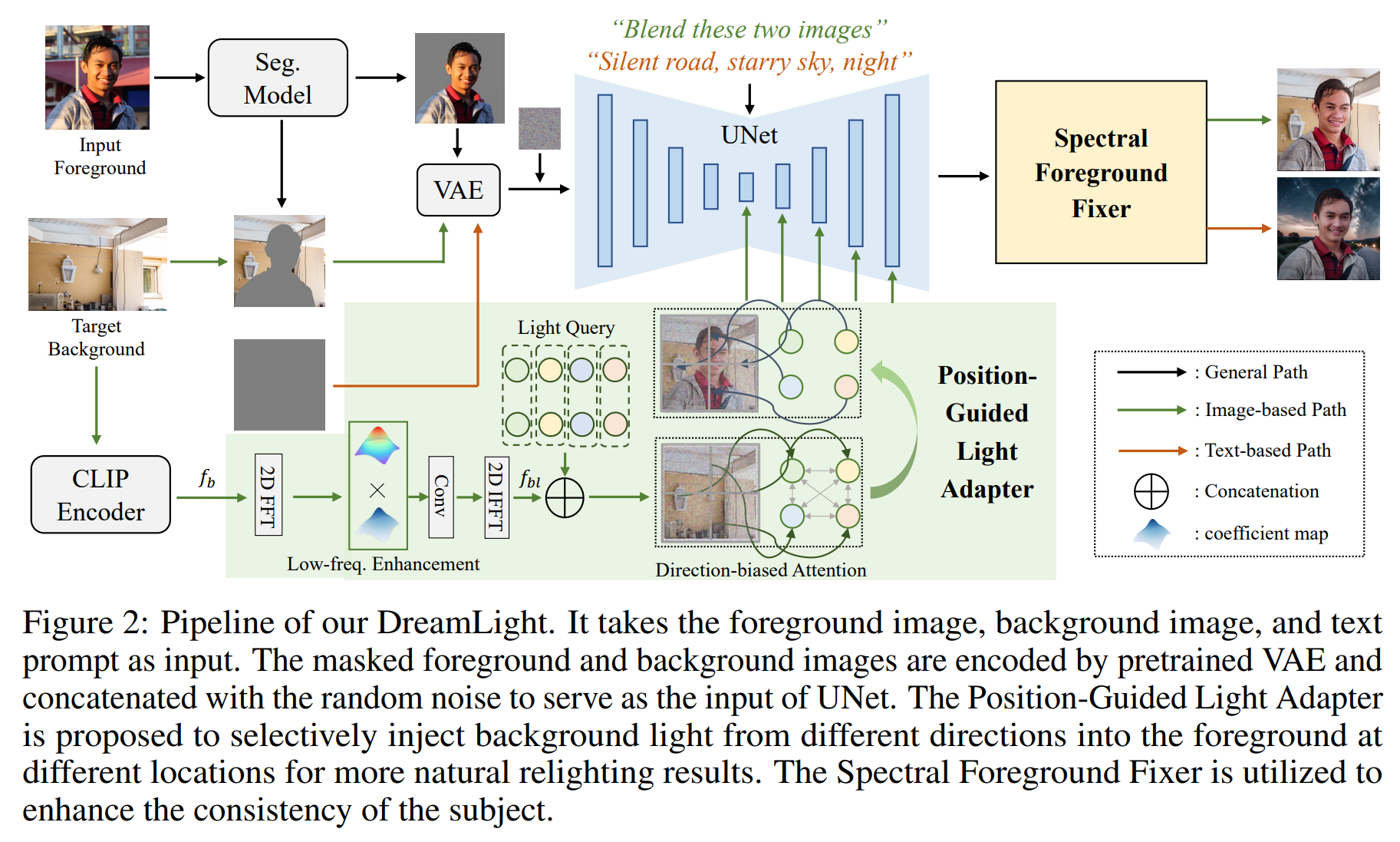
图2描述了DreamLight的整个流程图。 DreamLight输入是一个包含前景图像、背景图像和文本提示的三元组。对于基于图像的重照明,文本提示被设置为“融合这两张图片”。对于基于文本的重照明,背景图像则被设计为一张全黑图像。图2中的绿色和棕色线条分别展示了基于图像和基于文本的重照明的具体流程。详细来说,DreamLight首先利用一个预训练的分割模型来提取主体区域,并从输入图像中移除原始背景。遵循[40, 22]的方法,带掩码的主体和背景由VAE进行编码,然后与随机噪声拼接,作为扩散UNet的输入。对于基于图像的重照明,DreamLight提出了一个位置引导的光照适配器(PGLA),用以通过方向偏置的掩码注意力机制,将来自不同方向的背景光照信息选择性地注入到前景中。最后,DreamLight利用一个频谱前景修复器(SFF)来增强前景的一致性
Position-Guided Light Adapter
尽管简单地将背景与随机噪声拼接可以传递一些关于环境光照的信息,但这种方式施加的是一种像素对齐的光照先验,并且忽略了主体与来自背景不同方向光线之间的自然交互,因此在某些场景下会导致不理想的重照明结果。为了缓解这个问题,DreamLight提出了位置引导的光照适配器(PGLA)。它能增强前景对来自背景不同方向光源的响应,同时减少潜在的不合理光照对齐。这一目标的实现,是通过对背景光照信息进行额外的编码和组织来完成的。
特别地, PGLA 的整个Pipeline基于IP-Adapter的处理过程。DreamLight首先利用CLIP将目标背景图像编码为一个特征图 $f_{b} \in \mathrbb{R}_{H \times W \times C}$,其中 $\mathrm{C}$ 表示嵌入维度。为了减轻背景纹理对光照信息提取所产生的潜在噪声影响,DreamLight对编码后的背景特征执行了一项低频增强操作,这有助于强调宏观的光照与色调信息。该过程可以被公式化为:
\[\begin{equation} \begin{aligned} \mathrm{g} & =Gaussian(H,W,\sigma), \\ f_{bl} & =FFT(f_b)*g, \\ f_{bl} & =IFFT(ReLU(Conv(f_{bl})))+f_b, \end{aligned} \end{equation}\]由于背景图像是2D的自然图像,DreamLight因此认为光源方向可以分为:上下左右四个方向。然后DreamLight采用了一个如图所示的能够提取方向信息的掩码注意力机制。首先设计了四个方向的光照查询(Light Query)并且初始化。以 $f_{Q}^{left}$ 为例,生成一个与经过CLIP的背景图特征图尺寸相同,且光源从左往右衰减的coefficient map,记为“left decay map”。然后进行flatten以及乘上对应区域的初始化权重以适配交叉注意力机制,这使得 $f_{Q}^{left}$ 能够更加关注背景特征图左侧的信息。除此之外,DreamLight还将背景特征图以及light query 在维度上进行相加以得到交叉注意力的Key和Value。
下一步便是采用类似的掩码注意力机制,将它们的信息注入到 UNet 的潜在特征的前景区域中。具体来说,DreamLight 调整条件交叉注意力的权重,使得前景对象的不同区域能够对附近的光源产生更强的响应。除了交换 Q (查询) 和 K、V (键/值) 之外,DreamLight还额外为背景区域添加了一个掩码,以确保背景不被改变
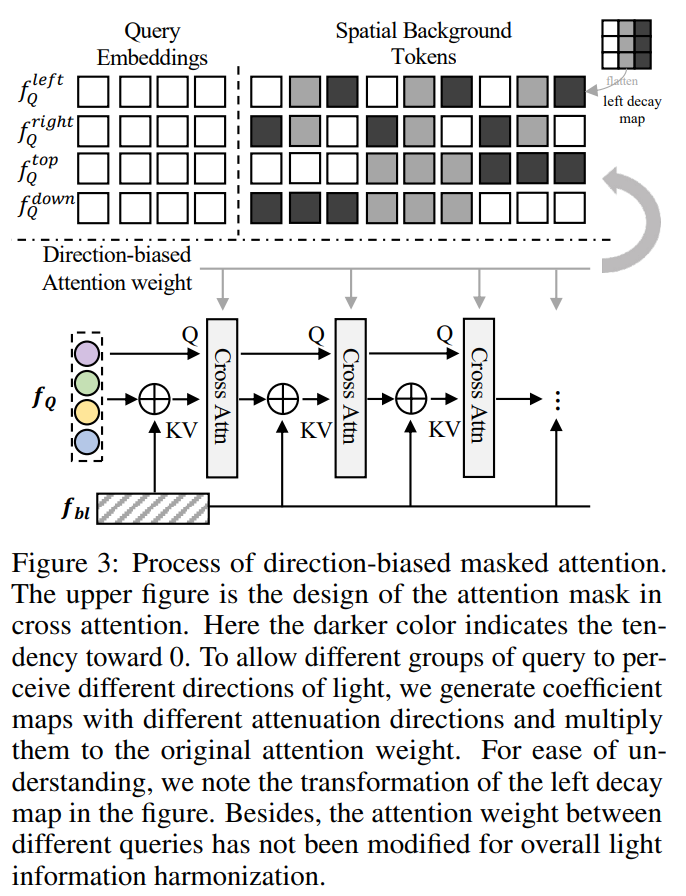
此外,DreamLight 仅在 UNet 的中间模块和上采样模块中注入这些光照先验。这是因为在下采样模块中改变特征可能会对整体语义产生影响。只需要根据对象的整体表示来改变其光照,这有助于避免因额外信息注入而导致的潜在失真问题
Spectral Foreground Fixer
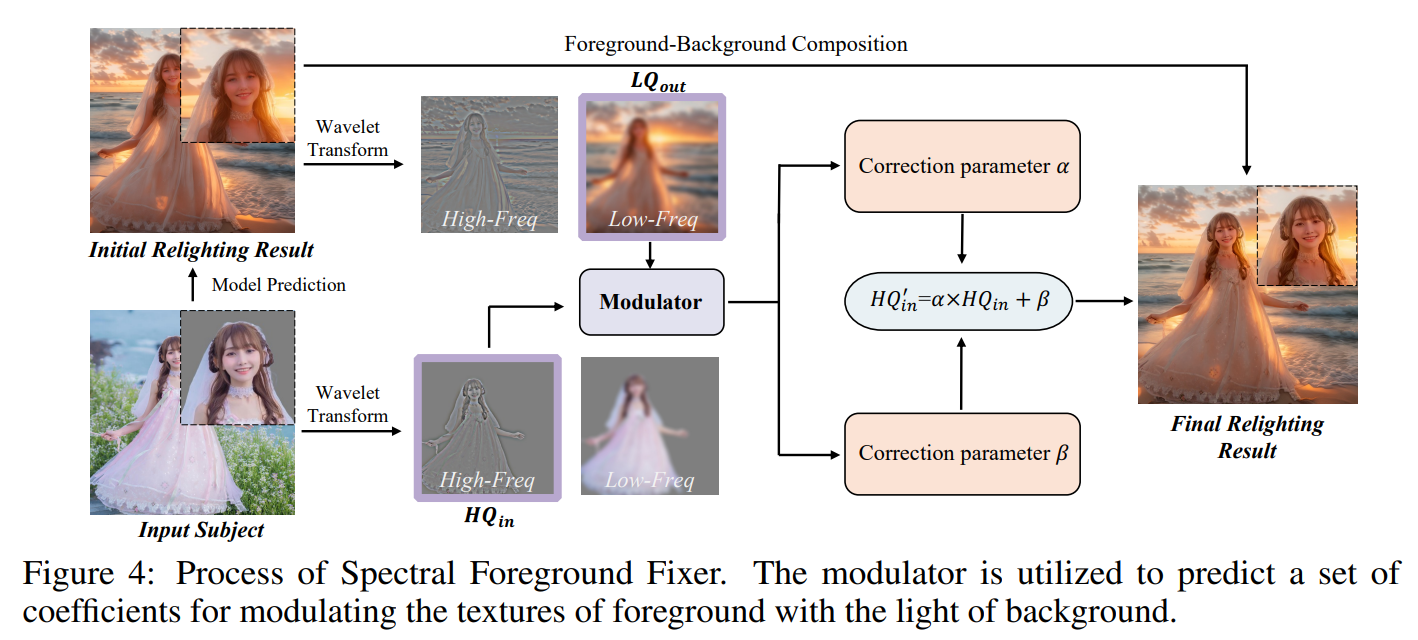
基于扩散的方法容易面临前景失真的问题,尤其是在面部和材质等细小且细节丰富的区域。提出了一个名为频谱前景修复器(Spectral Foreground Fixer, SFF)的模块以保持主体的纹理细节以及身份ID。该模块主要基于一个核心假设::图像的高频分量对应于剧烈变化的像素(例如物体边界和纹理),而低频分量则对应于宽泛的语义信息(例如颜色和光照)
如图4所示,DreamLight采用了小波变换来提取前景图像以及初始的预测结果图像的高频以及低频信息。可以发现,高配部分可以保持细节以及纹理,而低频部分展示了颜色以及色调。然后DreamLight将这些提取到的信息输入到一个Modulator之中,该Modulator将预测一组系数来重组然后以一定比例这些信息。获取重组系数的过程如下所示:
\[\begin{equation} \begin{aligned} \alpha,\beta=\mathcal{M}(HQ_{in},LQ_{out}), \\ HQ_{in}^{\prime}=HQ_{in}*\alpha+\beta, \\ I_{out}^\prime=HQ_{in}^\prime+LQ_{out}, \\ \end{aligned} \end{equation}\]Modulator $\mathcal{M}$ 是以一种自监督的方式进行单独训练的。具体来说,对任意的自然图像执行随机色彩变换,以获得伪造的成对重照明数据,其中变换后的图像作为输入,原始图像作为目标。然后,提取变换后图像的高频分量和原始图像的低频分量,并将它们作为 $\mathcal{M}$ 的输入,用于预测重组系数。
DreamLight 期望该调制器能够自适应地结合来自不同来源的高频和低频部分,并避免潜在的色彩噪声或伪影。DreamLight 利用 MSE(均方误差)损失和感知损失来监督学习过程。此外,为了提升训练的稳定性并改善协调性,监督被同时施加在预测结果的高频部分 $\mathrm{HQ}^{‘}{in}$ 和整个输出图像 $\mathrm{I}^{‘}{out}$
Data Generation
DreamLight 设计了一个数据生成流程来为模型的训练提供支持。DreamLight的数据有三个来源。
首先,通过以bootstrapping的方式训练一个重照明 ominicontrol LoRA 来构建数据对,即采用“训练 → 将结果纳入训练集 → 继续训练”的循环。初始数据集包含100对从延时摄影视频和作者拍摄的照片中采集的图像。每次训练后,该模型会被用来对普通图像进行重照明。高质量的结果会被筛选出来,并被整合到训练集中用于后续的训练。未来DreamLight将开源这个重照明LoRA。
其次,DreamLight利用可用的3D资产来渲染大量具有不同颜色和方向光照的一致性图像。在 3D Arnold 渲染器上构建了一个自动化渲染流程,并使用随机光源和HDR图像为相应的数据对生成各种光照效果。
最后,为了增强数据的多样性,DreamLight还使用 IC-Light 来处理普通图像,并利用美学评分模型筛选出高质量的合成数据对。其中的提示词通过一个两步流程生成:首先由 GPT-4 初步构思出超过200个基础场景,然后由 LLaVA 根据图像中出现的主要主体对这些场景进行定制化调整。
这三类数据的总量分别约为60万、15万和30万