X2Edit
Revisiting Arbitrary-Instruction Image Editing through Self-Constructed Data and Task-Aware Representation Learning

Abstract
Introduction
主要贡献:
构建了X2Edit数据集:一个规模庞大、质量优秀且任务均衡的图像编辑数据集。
设计了X2Edit模型:一个轻量级、即插即用且与社区主流模型兼容的编辑模块。
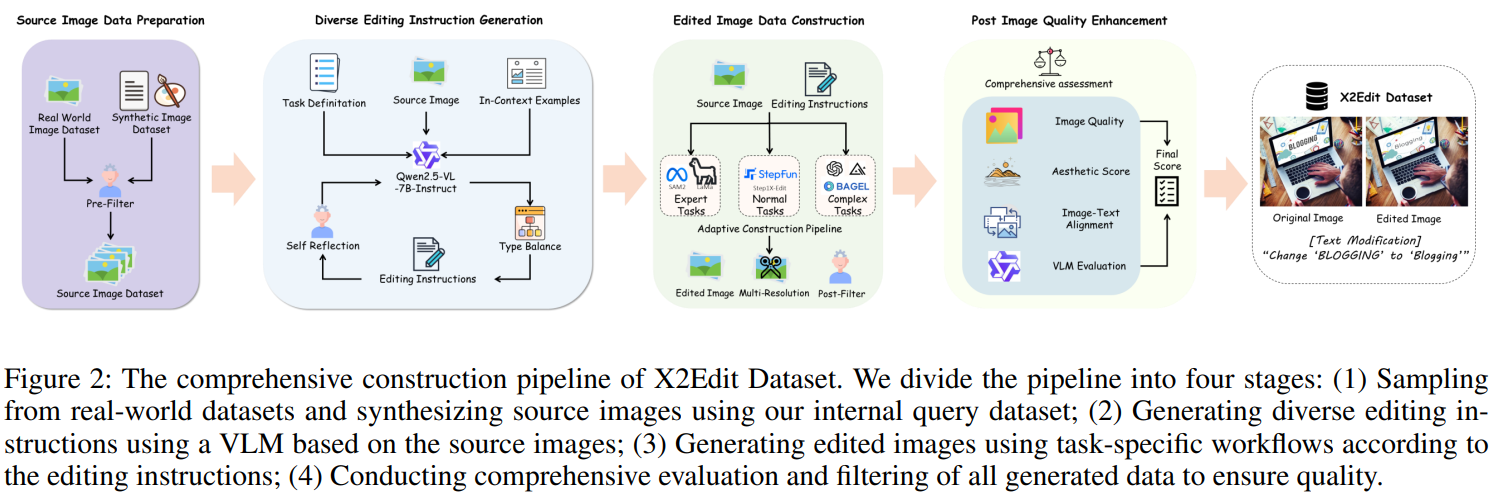
X2Edit Dataset
本文提出了 X2Edit 数据集,一个为任意指令编辑裁定的大规模、高质量、且各编辑任务数据均衡的数据集,数据集的构建流程如 Fig 2 所示,具体细节参考附录。
Automatic Dataset Pipeline
Source Image Preparation. 为了保证涵盖大多数类型真实世界的图像输入,大部分源数据来自 COYO-700M 和 LAION 数据集。为了符合主体驱动生成(subject-driven generation)这一任务的需要,本文还采用了内部查询结合使用 Shuttle-3-Diffusion 的方式来生成这一类数据。除此之外,本文还为数据集的构建设计了严格的数据筛查标准。具体地,只会保留高美学得分以及只保留 512 像素及以上的数据。而且,对于主体驱动生成任务,本文使用了 Qwen3 来保证内部查询的关键词是能够与前景中的主体匹配的。
Diverse Editing Instruction Generation. 由于图像描述不能够完整的捕捉到丰富的视觉细节信息,本文基于原图像,使用 Qwen2.5-VL-7B 来生成编辑指令。本文使用源图像,任务定义,前后文样本,以及严格设计的prompt来指导 VLM 直接从图像中生成编辑指令。为了避免 VLM 的幻觉现象,本文还设计了自反机制(self-reflection),即使用 VLM 自己来检查 VLM 生成的编辑指令。此外,本文还将各种任务的数据量做了平衡,以保证每一类数据量大体相同。
Edited Image Construction. 本文使用了闭源以及开源模型来根据不同的任务类型创建相应的数据集。比如,在主体添加和主体移除任务中,本文使用 RAM++ 以及 SAM2 作为分隔模型,
Post Quality Enhancement. 为了保证数据质量,本文使用了大量的框架来针对数据评估以及筛选。特别地,对于所有生成的图像,本文使用美学评分,比如 LIQE 和 CLIPIQA,能够大致地过滤掉一些质量不高的数据集。然后,为了保证编辑准确性,本文还使用了 ImgEdit-Judge 以及 Qwen2.5-VL-7B 来根据编辑指令、源图像、以及编辑后的图像,来评估以及过滤图像。对于主体驱动生成任务,本文使用 CLIP 和 DINO 分数来评估主体一致性。对于风格迁移任务,本文使用 Qwen2.5-VL-7B 来评估源图像以及生成图像之间的风格匹配度,以及应用过滤机制来进一步筛选。有关数据集筛选的进一步内容见附录。
Appendix
More Details About the X2Edit Dataset
在此,我仅关注跟 Relighting 任务相关的部分。git remote set-url origin
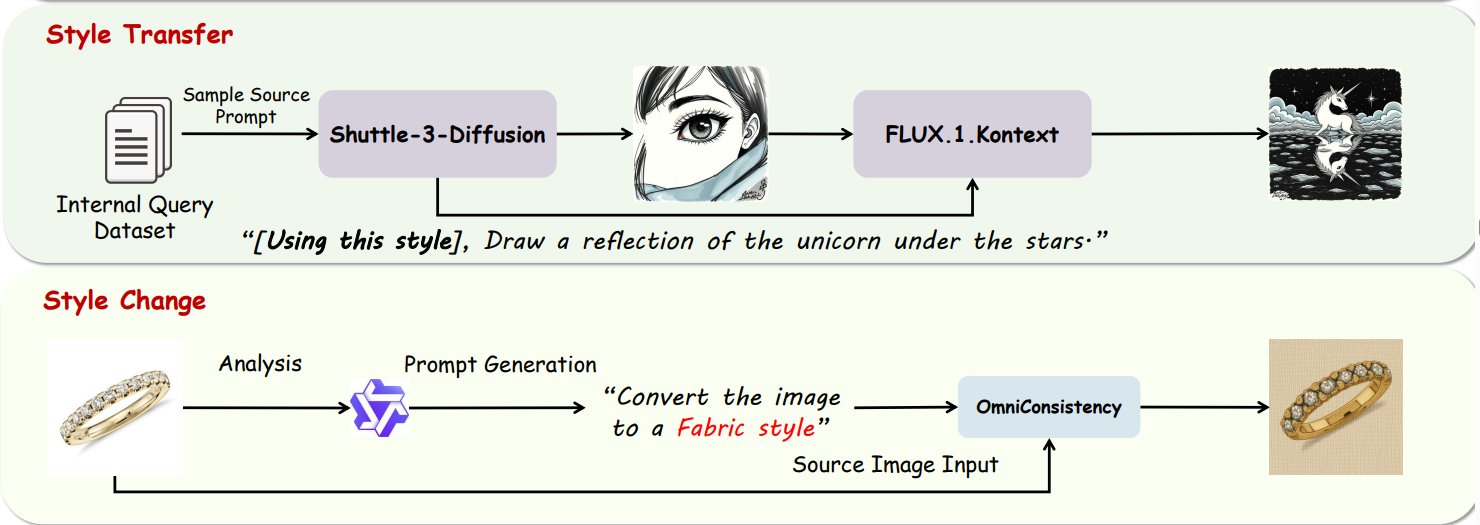
Style Transfer. 本文先从内部查询数据集中采样两个图像描述,其中一个用于输入到 Shuttle-3-Diffusion 中来生成推理图像(reference image),另一个用于输入到 Kontext 中来生成基于推理图像的风格的最终的编辑结果图像
Style Change. 本文根据采样到的源图像,使用 Qwen2.5-VL-7B 来随机挑选一种风格,并且建立这样的编辑指令:“Convert the image to a ** Style”,然后将这个编辑指令输入到 OmniConsistency 中来改变源图像的风格