RelightVid
RelightVid: Temporal-Consistent Diffusion Model for Video Relighting
研究任务
RelightVid 的核心任务是实现视频重光照,即在保持视频内容不变的前提下,修改视频中前景物体的光照条件,使其看起来像是在不同的光照环境下拍摄的。这一任务在影视制作、游戏开发、增强现实等领域具有重要的应用价值,例如可以用于调整场景的光照风格、增强视觉效果或适应不同的场景需求。
过去方法的问题
- 数据稀缺性:缺乏成对的视频重光照数据集,导致模型难以学习光照变化的时空一致性。
- 时空一致性:直接对视频逐帧应用图像重光照模型(如IC-Light)会导致显著的时空不一致性,因为生成模型的随机性使得相同输入可能产生多种不同的输出。
- 输入条件的局限性传统:方法依赖于复杂的输入(如HDR图像或球谐系数),在实际应用中不够灵活,用户更倾向于使用简单的文本提示或背景视频作为条件。
- 泛化能力不足:现有方法通常局限于人像或简单物体的重光照,难以处理复杂动态场景下的光照变化。
主要贡献
- 提出了一种灵活的视频重光照框架RelightVid,能够在不进行内在分解的情况下实现高质量的视频重光照。
- 构建了一个大规模的视频重光照数据集LightAtlas,包含真实视频和3D渲染数据,为模型训练提供了丰富的光照先验。
- 设计了一种高效的模型架构,通过时空注意力层和多模态条件输入,实现了高质量的视频重光照。
- 在多种条件下验证了RelightVid的性能,证明了其在时空一致性、光照合理性以及用户偏好方面的显著优势。
方法
数据集构造(LightAtlas)
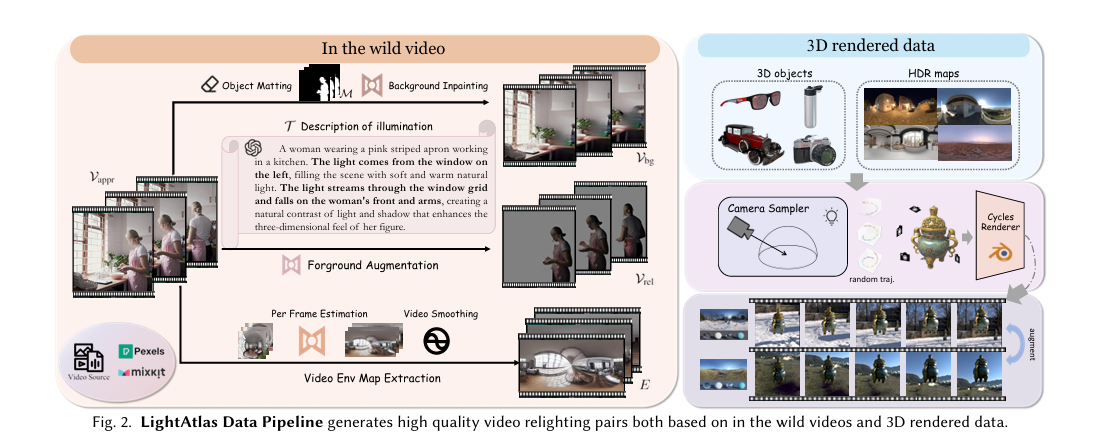
由于现有的配对视频重照明数据集稀缺,RelightVid提出了一个新的数据收集管道,称为LightAtlas。该数据集结合了真实场景视频和3D渲染数据,通过特殊设计的增强管道进行构建。
- 真实视频数据:从真实视频中提取前景物体和背景视频,通过图像重光照方法生成不同的光照条件下的前景视频。
- 3D渲染数据:利用Blender渲染器生成3D对象的视频数据,通过随机环境图和相机轨迹生成多样化的光照条件。
- 数据增强:对真实视频和3D渲染数据进行光照增强,生成大规模的成对视频数据。
通过对输入视频逐帧应用2D图像重照明方法(如IC-Light),生成重照明的前景视频。为了提取物体前景掩码,使用了抠图工具InSPyReNet。同时,利用DiffusionLight从视频中提取高动态范围(HDR)环境图,并通过时间卷积对其进行平滑处理。最终,模型生成了超过20万对高质量视频编辑样本。
模型架构
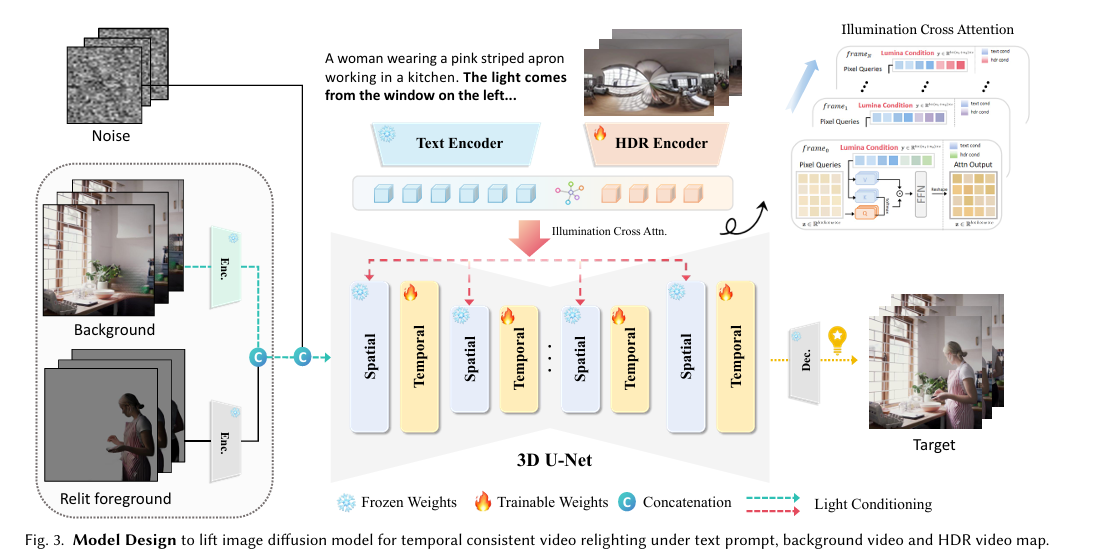
- 基础模型:采用预训练的2D图像重光照扩散模型(如IC-Light)作为基础模型,利用其图像重光照先验。
- 时空扩展:将2D模型扩展为3D U-Net,引入时空注意力层,捕捉视频帧之间的时空依赖关系。为增强时间一致性,模型中集成了时间注意力层。训练过程中,空间层被冻结,只微调时间层,以保持IC-Light的编辑能力并确保对域外案例的良好泛化能力。
- 多模态条件编码: 背景视频和重光照视频:通过VAE编码器将背景视频和重光照视频编码到潜在空间。 HDR环境图:通过5层MLP将HDR环境图编码为LDR和HDR特征。 文本提示:通过CLIP文本编码器将文本提示编码为特征向量。
- 条件注入:通过VAE编码器分别编码重照明视频($V_{rel}$)和背景视频($V_{bg}$),并将其 latent 表示($z_{rel}$ 和 $z_{bg}$)与添加的噪声结合,将编码后的条件特征通过交叉注意力机制注入到模型中,实现精确的光照控制。
训练与优化
多模态条件联合训练:RelightVid的一个创新点是实现了多模态条件的联合训练。通过同时考虑背景条件和文本提示,可以实现更细粒度的光照控制。模型通过优化以下目标函数进行训练: \(\begin{equation} \min_\theta\mathbb{E}_{z\sim\mathcal{E}(x),t,\epsilon\sim\mathcal{N}(0,1)}\|\epsilon-\epsilon_\theta(z_t,t,\hat{\mathcal{E}})\|_2^2, \end{equation}\) \(\begin{equation} \hat{\mathcal{E}}=\{\mathcal{E}_i(z_{rel}),\mathcal{E}_i(z_{bg}),\mathcal{E}_t(y),\mathcal{E}_e(E)\}, \end{equation}\) 其中,$\hat{\mathcal{E}}$ 是关于输入视频、背景视频、环境图和CLIP嵌入的编码条件latent。
光照不变性集成(IIE):为增强重照明的鲁棒性,论文还提出了一种光照不变性集成(Illumination-Invariant Ensemble, IIE)策略。该策略通过对输入视频施加多种亮度增强,生成多个增强版本,然后平均每个增强版本的噪声预测,以获取更可信的最终结果。这种方法可以显著减轻光照变化对重照明质量的影响。
LightAtlas Data Collection Pipeline
每一个(appearance video)外观视频 $\mathcal{V}_{\mathrm{appr}}\in\mathbb{R}^{f\times h\times w\times3}$ 与五种增强数据配对以促进光照建模:
\[\mathcal{V}_{\mathrm{appr}}\leftrightarrow\{\mathcal{V}_{\mathrm{rel}},\mathcal{V}_{\mathrm{bg}},E,\mathcal{T},\mathcal{M}\},\]其中 $\mathcal{V}{\mathrm{rel}}\in\mathbb{R}^{f\times h\times w \times 3}$ 表示重光照后的前景视频,$\mathcal{V}{\mathrm{bg}} \in \mathbb{R}^{f\times h\times w \times 3}$ 表示背景视频, $\mathrm{E} \in \mathbb{R}^{f\times 32 \times 32 \times 3}$ 表示卷积后的时间环境图,\mathcal{T} 表示光照变化的文本描述以及 $\mathcal{M}\in\mathbb{R}^{f\times h \times w}$ 表示前景掩码。
给定真实世界的视频 $\mathcal{V}{\mathrm{appr}}$ , 由2D的重光照模型 IC-Light 逐帧进行打光得到增强后的在不同光照条件下的重光照前景视频 $\mathcal{V}{\mathrm{rel}}$ 。然后分别使用 InSPyReNet 以及 ProPainter 获得前景掩码 $\mathcal{M}$ 以及补齐后的背景视频 $\mathcal{V}\mathrm{bg}$ 。而HDR环境图则使用 DiffusionLight 从 $\mathcal{V}\mathrm{appr}$ 中提取以及通过temporal convolution后得到。除此之外,还是用 GPT-4V对视频的环境以及光照细节进行达标,以及进一步进行过滤后得到大约20K的高质量原视频数据。
在增强数据对中,背景视频 $\mathcal{V}\mathrm{bg}$ ,环境地图 $\mathrm{E}$ 和光照描述 $\mathcal{T}$ 被作为条件输入,重光照视频 $\mathcal{V}\mathrm{rel}$ 作为模型输入,而真实世界的视频 $\mathcal{V}{\mathrm{appr}}$ 则作为目标视频。因为 $\mathcal{V}{\mathrm{appr}}$ 是从真实场景中获取,因此将 $\mathcal{V}_{\mathrm{appr}}$ 作为目标视频可以使得模型学习到真实的数据分布以及每帧之间的时间连贯性(temporal coherence)。虽然这部分数据具有很高的照片真实感,但某些输入光照条件,尤其是环境贴图(HDR),由于估算过程会引入噪声。为了提升HDR视频的精确光照条件,作者还引入了来自3D渲染引擎的辅助训练数据,以实现更精确的控制,并提升模型对多样化光照场景的鲁棒性。通过输入增强,包括亮度缩放和基于阴影的重光照处理,最终生成了20万对高质量的视频编辑样本。