Q-Insight
Q-Insight:Understanding Image Quality via Visual Reinforcement Learning
Abstract
图像质量评价(IQA)关注于图像的感知视觉质量,在图像重建、压缩和生成等下游任务中发挥着关键作用。多模态大语言模型(MLLMs)的快速发展极大地拓展了IQA的研究范围,使其朝着更全面的图像质量理解方向发展,不仅包括内容分析、退化感知,还包括超越单纯数值评分的比较推理。以往基于MLLM的方法通常要么只生成缺乏可解释性的数值分数,要么严重依赖于使用大规模标注数据集进行有监督微调(SFT)来提供描述性评估,从而限制了其灵活性和适用性。本文提出了一种基于强化学习的模型Q-Insight,该模型基于群体相对策略优化(GRPO),在图像质量理解方面展现出强大的视觉推理能力,同时仅需少量的评分和退化标签。通过联合优化分数回归和退化感知任务,并设计精细的奖励函数,作者的方法能够有效利用两者的互补优势,从而提升整体性能。大量实验表明,Q-Insight在分数回归和退化感知任务上均大幅优于现有的最新方法,同时展现出令人印象深刻的zero-shot泛化能力和卓越的比较推理能力。
Introduction
现存的基于大语言模型的IQA方法可以分为两类:基于分数的方法,比如Q-Align和DeQA-Score,以及基于描述的方法,比如DepictQA和DepictQA-Wild。基于分数的方法将离散的标注转化为连续的质量分数,从而提升了适应性,但通常牺牲了可解释性,并忽视了多模态大语言模型(MLLMs)本身的推理和描述能力。同时,仅仅地回归一个质量分数在某些场景下可能并不具有实际意义,因为图像质量分数具有主观性,用户对于不同的图像存在偏见,并且在不同数据集和内容类型之间缺乏统一标准。例如,在评估AIGC生成的数据时,非同寻常的视觉效果和鲜艳的色彩通常意味着更高的质量;然而,在评估超分辨率结果时,这些特征却常常被认为过于“画风化”,导致图像失真,丧失真实性和保真度。相反,基于描述的方法能够生成关于图像退化和对比评估的详细文本解释,保证了可解释性,但又极度依赖于大量文本描述进行有监督微调。此外,这类模型无法输出精确的分数,因此不适合作为损失函数或用于图像质量的准确排序。因此,将数值评分与描述性推理整合到一个统一且可解释的、基于MLLM的IQA框架中,依然是一个重要但尚未解决的挑战。
总结一下本文的贡献:
- 提出了Q-Insight,这是首个专为全面图像质量理解而设计的推理型多模态大语言模型。与以往严重依赖详细文本描述进行有监督微调(SFT)的方法不同,本文提出的方法仅利用有限的主观评分或退化标签,就能实现卓越的理解能力
- 提出了一个统一的框架,能够联合优化图像质量评分和退化感知,揭示了各任务之间的互补优势。在该框架下,设计了三种专门的奖励机制,包括可验证的分数奖励、退化分类奖励以及退化强度感知奖励,使GRPO框架能够有效泛化到low-level视觉应用中。
- 在多个不同数据集和IQA任务上的大量实验表明,Q-Insight在性能上始终优于现有的基于模型的IQA指标以及依赖SFT的大语言模型。此外,它在诸如基于参考的图像比较推理等未见过的任务上也展现出令人印象深刻的零样本泛化能力,突显了本文方法的鲁棒性和多样性。
Methodology
Preliminaries
Group Relative Policy Optimization (GRPO) 是一种创新的强化学习范式,已被广泛应用于如 DeepSeek R1-Zero 等模型中。不同于需要显式评论家模型来评估策略模型性能的Proximal Policy Optimization (PPO),GRPO 通过直接比较从策略模型中采样的一组响应来计算优势,大大减轻了计算负担。特别地,给定一个查询 $q$,GRPO会从旧的策略模型 $\pi_{\theta_{\mathrm{old}}}$ 中采样 $N$ 个离散的responses ${o^{(1)},o^{(2)},\ldots,o^{(N)}}$ 。然后执行对应的行为(actions)并根据特定的任务规则收到各自的奖励 ${r^{(1)},r^{(2)},\ldots,r^{(N)}}$。通过计算奖励的均值和标准差,可以得到每个 response 的相对优势,具体如下:
\[\begin{equation} \hat{A}^{(i)}=\frac{r^{(i)}-\max(\{r^{(1)},r^{(2)}\ldots,r^{(N)}\})}{\mathrm{std}(\{r^{(1)},r^{(2)}\ldots,r^{(N)}\})}, \end{equation}\]其中 $\hat{A}^{(i)}$ 表示第 $i$ 个response 的归一化相对质量。总体而言,GRPO 引导策略模型优先选择在同一组中获得更高奖励值的高质量答案。在获得了 $\hat{A}^{(i)}$ 后,GRPO 会计算每一个采样出的样本在新的策略模型 $\pi_{\theta_{\mathrm{new}}}$ 以及旧的策略模型 $\pi_{\theta_{\mathrm{old}}}$ 下的概率比值,记为 $\rho^{(i)}$ 。为了防止模型更新过大并稳定训练过程,GRPO 将 $\rho^{(i)}$ 限制在 $\left [ 1-\delta ,1+\delta \right ]$ 的范围内。为了不与参考分布 $\pi_{\mathrm{ref}}$ 的差距太大(即不能一次偏离参考分布太远),引入了由 $\beta$ 加权的 KL 散度惩罚项。最终,GRPO 的优化目标可以表述如下:
\[\begin{equation} \mathcal{J}(\theta)=\mathbb{E}_{[q\thicksim Q,o^{(i)}\thicksim\pi_{\theta_{\mathrm{old}}}]}\left\{\min\left[\rho^{(i)}\hat{A}^{(i)},\operatorname{clip}\left(\rho^{(i)},1-\delta,1+\delta\right)\hat{A}^{(i)}\right]-\beta\cdot\mathbb{D}_{\mathrm{KL}}[\pi_{\theta_{\mathrm{new}}}||\pi_{\mathrm{ref}}]\right\} \end{equation}\]其中 $\rho^{(i)}=\pi_{\theta_{\mathrm{new}}}(o^{(i)}\mid q)/\pi_{\theta_{\mathrm{old}}}(o^{(i)}\mid q)$ , $\mathrm{Q}$ 表示供选择的候选问题组, $\mathbb{D}{\mathrm{KL}}$ 表示KL正则。 $\pi{\mathrm{ref}}$ 通常是一个冻结的预训练多模态大模型(MLLM)。GRPO 有效地在一致性策略更新和强奖励信号之间实现了平衡整合。据作者所知,作者是首个将 GRPO 应用于图像质量理解任务的工作,这使得作者的模型能够在不依赖大量标注数据的情况下,实现稳健的推理和泛化能力。
Overview
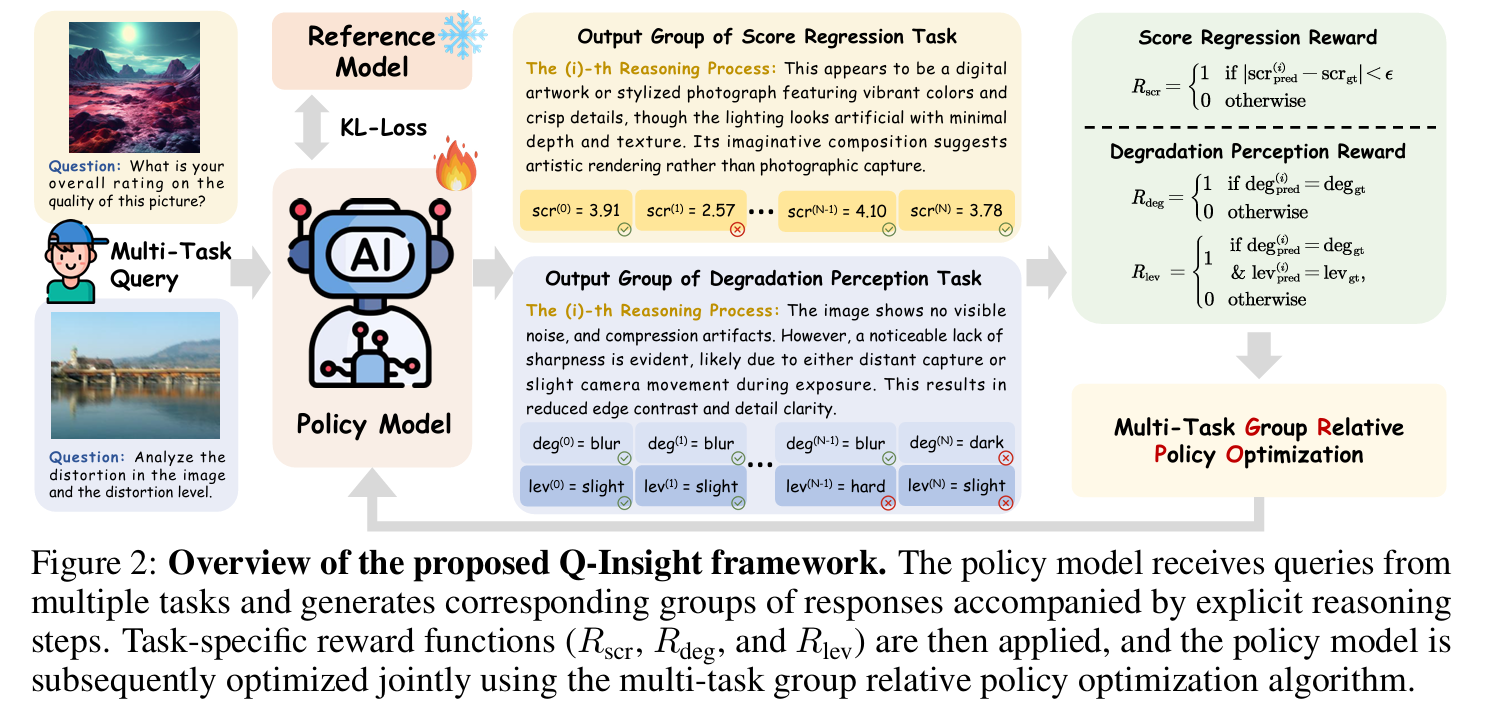
在训练阶段,会共同优化分数回归和退化感知这两个任务(score regression and degradation perception)。具体地,由一张图像以及与任务适配的问题组成多模态输入。给定输入后,策略模型 $\pi_{\theta}$ 生成几组回答,没组回答都有详细地推理步骤。随后,每一组回答会使用对应的奖励函数 $R_{\mathrm{scr}}$(用于分数回归)和 $R_{\mathrm{deg}}$(用于退化感知)进行评估。在计算完每一组回答的奖励后,策略模型 $\pi_{\theta}$ 会通过多任务GRPO算法进行共同优化。此外,KL散度损失会被采用以限制策略模型 $\pi_{\theta}$ 和 推理模型 $\pi_{\mathrm{ref}}$ 的偏移。在推理阶段,已训练的Q-Insight能够产生连贯的推理过程以及输出准确的回答。
Multi-Task Group Relative Policy Optimization
如图2所示,对于每一个输入图像对,策略模型产生一组共 $\mathbf{N}$ 个responses,记为 $\left{r^{(i)}\right}{i=1}^N$ ,然后使用奖励函数 $R{\mathrm{scr}}, R_{\mathrm{deg}}, R_{\mathrm{lev}}$ 对responses进行评估,获得整个奖励 $\left{r^{(i)}\right}_{i=1}^N$ 。设计合适的奖励函数是至关重要的一环
Format reward。该奖励用于评估推理步骤是否合理的包含标签“<think>”和“</think>” ,以及最终回答是否包含标签“<answer>”和“</answer>”。除此之外,还要求回答内容要符合json-like的格式,即需要由 “{” 开始,并且由 “}” 结尾,且不能包含额外的 “{” 和 “}”。这种json-like的格式要求可以确保Q-Insight在不同任务直接一致性地parse回答。奖励分数 $r_{\mathrm{fmt}}^{(i)}$ 被设置为一个二值函数:对于第 $i$ 个response,如果满足上述条件,$r_{\mathrm{fmt}}^{(i)}$ 为1,否则为0。
Rewards for score regression task。一种标准的方法来量化图像质量是使用Mean Option Score(MOS)。 不同于直接使用大语言模型(MLLM)的预测来拟合MOS,本文使用MOS作为一个通用准则(general guideline) 来鼓励模型在评估图像质量的过程中更加深入地推理以及生成更加深刻的观点。受DeepSeek-R1的启发,本文将连续的MOS预测视为一种二值化结果,这样可以避免极大或者极小的奖励值。将第 $i$ 个response的预测得分记为 $\mathrm{scr}{\mathrm{pred}}^{(i)}$ 以及ground-truth得分记为 $\mathrm{scr}{\mathrm{gt}}$ ,那么第 $i$ 个response 的奖励值 $r_{\mathrm{scr}}^{(i)}$ 为:
\[\begin{equation} r_{\mathrm{scr}}^{(i)}=1\quad\mathrm{~if~}|\mathrm{~scr}_{\mathrm{pred}}^{(i)}-\mathrm{~scr}_{\mathrm{gt}}|<\epsilon,\mathrm{~otherwise~}0, \end{equation}\]其中 $\epsilon$ 是一个预定义的阈值。
Rewards for degradation perception task。发现,仅使用分数标签进行训练会导致模型对图像细节退化(如 JPEG 压缩)的感知能力较差。这可能是因为通用的多模态模型在预训练时主要关注高层语义信息,从而忽略了细微的低层失真。为了解决这个问题,作者将模型与一个退化感知任务联合训练,利用易于获取的退化标签,从而增强模型对这些图像退化的敏感性。在该任务中,模型需要同时预测失真类型(distort class)和相应的失真等级(distort level)。由于失真类型和等级本质上都是离散变量(discrete variables),作者为该任务同样设计了二元奖励机制。将第 $i$ 个response的预测失真类型和等级分别记为 $\mathrm{deg}{\mathrm{pred}}^{(i)}$ 和 $\mathrm{lev}{\mathrm{pred}}^{(i)}$ ,那么对于 $i$ 个response 的奖励值 $r_{\mathrm{deg}}^{(i)}$ 为:
\[\begin{equation} r_{\mathrm{deg}}^{(i)}=1\quad\mathrm{~if~deg}_{\mathrm{pred}}^{(i)}=\mathrm{~deg}_{\mathrm{gt}},\mathrm{~otherwise~}0. \end{equation}\]类似地,对于 $i$ 个response 的奖励值 $r_{\mathrm{lev}}^{(i)}$ 为:
\[\begin{equation} r_{\mathrm{lev}}^{(i)}=1\quad\mathrm{~if~deg}_{\mathrm{pred}}^{(i)}=\mathrm{deg}_{\mathrm{gt}}\mathrm{~and~lev}_{\mathrm{pred}}^{(i)}=\mathrm{lev}_{\mathrm{gt}},\mathrm{~otherwise~}0. \end{equation}\]Overall multi-task reward。
Data Construction
作者构建了多模态训练数据,以在分数回归任务和退化感知任务上对 Q-Insight 进行联合训练。对于分数回归任务,输入包括一个特定任务的提示语和待评分的图像,平均主观评分(MOS)作为计算相应奖励的依据。在退化感知任务中,输入由一个提示语和一张具有特定失真类型及严重程度的图像组成。失真类型分为五类:“noise”、“blur”、“JPEG”、“darken”和“null(无失真)”,其中“null”表示图像未受损。每种失真类型又分为五个严重程度:“slight”、“moderate”、“obvious”、“serious”和“catastrophic”。失真类型和相应的严重程度共同构成了用于计算退化分类和强度感知奖励的真实标签。总体而言,作者精心设计的基于GRPO的框架和多任务训练策略,使Q-Insight即使在标注有限的情况下,也能实现稳健的推理和感知能力。更重要的是,这种灵活的方法有助于在多种低层视觉应用中实现有效的泛化,正如实验所展示的那样,充分体现了作者框架在应对实际视觉任务中的优势。
Experiments
Experimental Setup
Datasets and Metrics。对于分数回归任务,作者在四类不同的图像质量评价(IQA)数据集上进行训练:(a)真实场景数据集,包括 KonIQ 、SPAQ 和 LIVE-Wild;(b)合成失真数据集,包括 KADID 和 CSIQ;(c)模型处理失真数据集,包括 PIPAL;以及(d)AI 生成图像数据集 AGIQA。按照 (Teaching large language models to regress accurate image quality scores using score distribution.)的做法,作者将 KonIQ 划分为训练集和测试集,训练集约包含 7000 张图像。所有数据集的平均主观评分(MOS)都被归一化到 [1, 5] 区间。其余数据集仅用于评估模型的分布外(OOD)泛化能力。
对于退化感知任务,作者从 DQ-495K 数据集中随机选取 7000 张仅包含单一失真的图像用于训练,另外保留 1000 张图像用于测试。作者采用皮尔逊线性相关系数(PLCC)和斯皮尔曼等级相关系数(SRCC)作为分数回归任务的评估指标。对于退化感知任务,作者使用失真类型和退化等级的准确率作为评估指标。
Implementation Details。采用Qwen-2.5-VL-7B-Instruct作为base model。在GRPO算法,生成样本的数量 $N$ 设置为 8,KL散度的惩罚权重 $\beta$ 设置为 $1 \times 10^{-3}$,而权重 $\alpha_{1}$ 和 $\alpha_{2}$ 分别设置为 0.25 和 0.75 。阈值 $\epsilon$ 设置为 0.35。
Appendix
Experimental Setups and More Results of Comparison Reasoning
在训练过程中,作者使用了 DiffIQA 数据集,该数据集包含约 18 万对参考图像与测试图像对,这些测试图像是通过对不同质量的参考图像应用基于扩散的方法增强生成的。每张参考图像都对应多张测试图像,并由人工标注者通过三元组比较的方式给出偏好标签,最终得到约 18 万对比较样本。值得注意的是,A-Fine 汇集了 DiffIQA、TID2013 、KADI 和 PIPAL 等数据集,总计用于训练的比较对超过 20 万。而相比之下,作者仅从 DiffIQA 中随机采样了 5000 对用于训练。
在评估阶段,作者采用了 SRIQA-Bench ,这是一个专门用于评估 IQA 模型在真实世界超分辨率(SR)场景下泛化能力的基准数据集。该数据集包含 100 张低分辨率(LR)参考图像,每张图像都由 10 种不同的超分辨率方法增强,这些方法涵盖了回归型和生成型模型。人工评审者对每组图像进行了详尽的两两比较,每个比较对至少有 10 位标注者参与,以确保标注的可靠性。由于没有提供真实的高分辨率参考图像,模型必须仅基于退化的 LR 图像来评估感知质量。因此,SRIQA-Bench 为全面参考型 IQA 模型在不完美参考条件下的鲁棒性评估提供了极具挑战性的场景。
作者报告了 Reg-Acc、Gen acc 和 overall ACC,分别表示在回归型 SR 方法、生成型 SR 方法以及所有 SR 输出上的两两排序准确率。这些指标衡量了模型预测与人工判断在不同超分辨率风格和失真特性下的一致性。作者还报告了基于描述方法的 PLCC 和 SRCC 指标。