IllumiCraft
IllumiCraft: Unified Geometry and Illumination Diffusion for Controllable Video Generation
Abstract
尽管扩散模型能够从文本或图像输入生成高质量、高分辨率的视频序列,但在跨帧控制场景光照和视觉外观时,扩散模型缺乏对几何线索的显式整合。为了解决这一局限性,本文提出了IllumiCraft:一个端到端的模型,能够接受三种互补的输入:(1)用于精细光照控制的高动态范围(HDR)视频图;(2)通过合成重光照并随机改变照明条件的帧(可选地与静态背景参考图像配对),以提供外观线索;以及(3)捕捉精确三维几何信息的三维点轨迹。通过在统一的扩散架构中整合光照、外观和几何线索,IllumiCraft 能够生成与用户自定义提示一致的时序连贯视频。它支持基于背景和基于文本的视频重光照,并且在保真度方面优于现有的可控视频生成方法。
Introduction
本文工作的主要贡献如下:
- 提出了一种统一的扩散架构,将光照和几何引导共同整合,实现了高质量的视频重光照。该方法支持基于文本和基于背景的视频重光照。
- 引入了一个高质量视频数据集,包含20,170对视频样本,涵盖了配对的原始视频与同步重光照视频、HDR图和三维跟踪视频。该数据集不仅支持视频重光照任务,也为更广泛的可控视频生成任务提供了宝贵资源。
- 进行了大量评测,展示了本文提出的模型在视频重光照任务上相较于最新方法的有效性。
Method
本文提出了 IllumiCraft,一种统一的扩散模型,能够联合利用几何和光照线索,实现可控的视频生成。首先,介绍了 IllumiPipe——本文用于数据收集的流程,该流程从真实视频中构建了一个高质量的数据集,包含HDR环境图、三维跟踪视频序列以及合成重光照的前景片段。接下来,详细阐述了 IllumiCraft 的核心架构,该架构在单一体系中融合了外观、几何和光照引导。最后,分别介绍了训练策略和推理流程,重点说明了每个组件如何促进高保真、可控的视频生成。
IllumiPipe
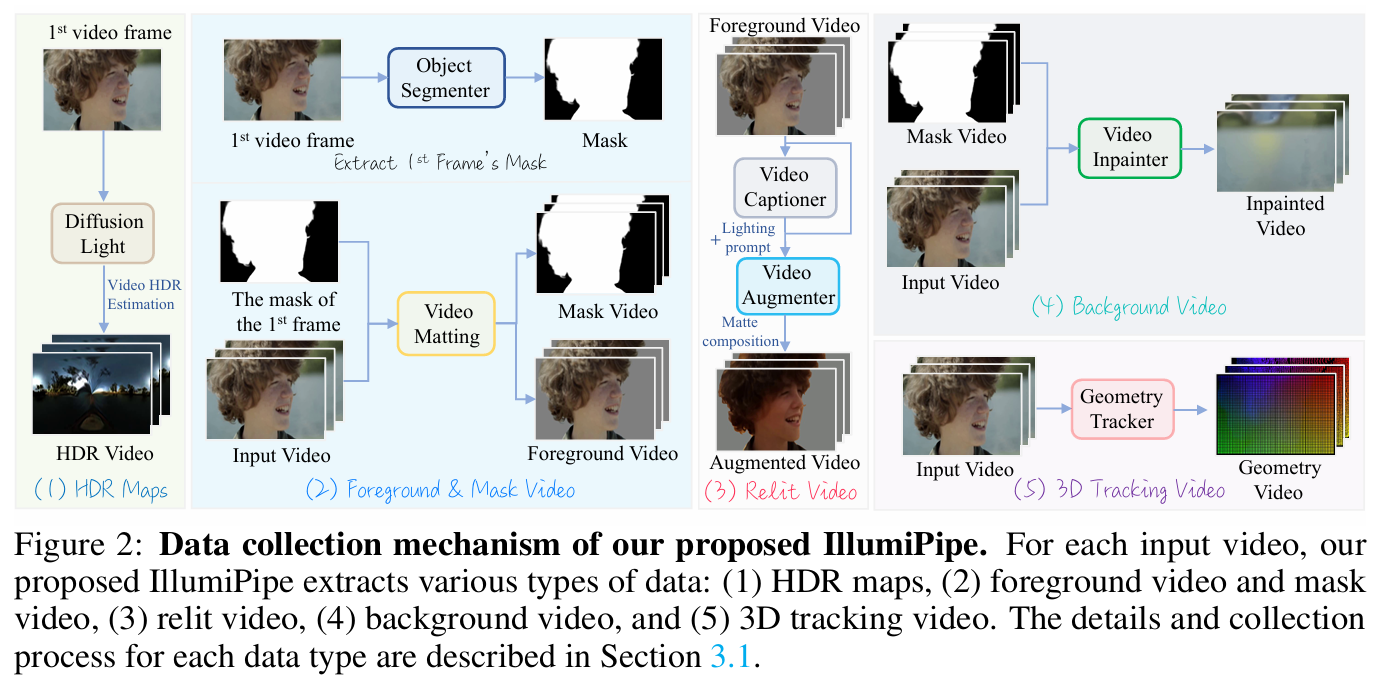
收集带有全面标注的配对视频数据集,对于训练能够支持高保真视频重光照的强大视频生成模型至关重要。然而,现有的公开视频数据集很少同时包含HDR环境图和三维跟踪序列,这限制了视频重光照和基于几何的视频编辑性能的提升。为了解决这一问题,本文提出了 IllumiPipe——一个高效的数据收集流程,能够从真实世界的视频中提取HDR环境图数据、重光照视频片段以及精确的三维跟踪视频序列。Figure 2展示了 IllumiPipe 的详细工作流程。
每一个(appearance video)外观视频 $\mathcal{V}_{\mathrm{appr}}\in\mathbb{R}^{f\times h\times w\times3}$ 与6个增强数据配对以促进光照建模(RelightVid 是5个):
\[\mathcal{V}_{\mathrm{appr}}\leftrightarrow {\mathcal{V}_{\mathrm{ref}},\mathcal{V}_{\mathrm{bg}},\mathcal{V}_{\mathrm{hdr}},\mathcal{V}_{\mathrm{geo}},\mathcal{V}_{\mathrm{mask}},\mathcal{C}},\]其中 $\mathcal{V}_{\mathrm{mask}} \in \mathbb{R}^{T \times H \times W \times 3}$,(这与RelightVid的Mask的通道数不一样)$T$ 表示帧数,$W$ 表示视频的宽,$H$ 表示视频的高。
HDR Environment Maps. 由于HDR maps可以进行准确的基于图像的照明,本文利用DiffusionLight 来提取这些HDR maps。然而,由于DiffusionLight是为单张图像设计的,如果对每一帧视频独立应用该方法,会导致严重的时间不一致性,即合成的铬球在不同帧之间往往变化很大。为保证时间上的稳定性,本文仅从每个视频的第一帧提取铬球图像,然后将这一初始铬球直接复制到后续所有帧,从而在整个序列中获得时间连贯的HDR视频 $\mathcal{V}_{\mathrm{hdr}}$。
具体来说,给定第一帧中通过DiffusionLight提取的铬球图像,使用Video Depth Anything 为视频获取深度图。随后,在各帧之间跟踪一组稀疏且可靠的图像点,(2)利用这些点的深度值通过受限仿射拟合推断相机的三维运动,(3)将该运动应用于参考铬球:将其像素提升到代表性深度,通过估算的变换和相机内参进行投影,并重采样以估算当前帧的铬球图像。关于整个过程的更多细节,在附录中进行了详细说明。
Video Captions。为了为每个视频生成详细的描述,我们采用 CogVLM2-VideoLLaMA3-Chat,并使用如下提示词:“请仔细观看视频,并生动详细地描述其内容、物体的运动、光照和氛围,重点突出物体的运动(例如,缓慢向左漂移、快速向前冲刺、上下弹跳、轻柔上升)、光照条件(例如,红蓝霓虹灯、自然阳光、摄影棚聚光灯、科幻RGB光辉、赛博朋克霓虹、海上日落或魔法森林照明)以及整体氛围(例如,温暖、情绪化、空灵、舒适、都市粗犷或未来迷雾)。” 该提示词引导模型生成强调视觉内容、物体运动、光照和整体氛围的丰富描述。
3D Tracking Videos。对于真实外观视频 $\mathcal{V}_{\mathrm{appr}}$,由于无法获得真实的几何信息,采用 SpatialTracker,直接在三维空间中检测和定位显著的三维兴趣点。为每个视频初始化一个包含4900个点的均匀网格,以确保场景空间的均匀覆盖。对于每一对连续帧,SpatialTracker 会估算这些点的三维位置,并通过学习到的空间匹配计算它们之间的对应关系。最终输出的是一组密集且时序连贯的三维点轨迹,即使在无约束和动态环境下,也能较好地逼近场景的真实运动。
Model Architecture
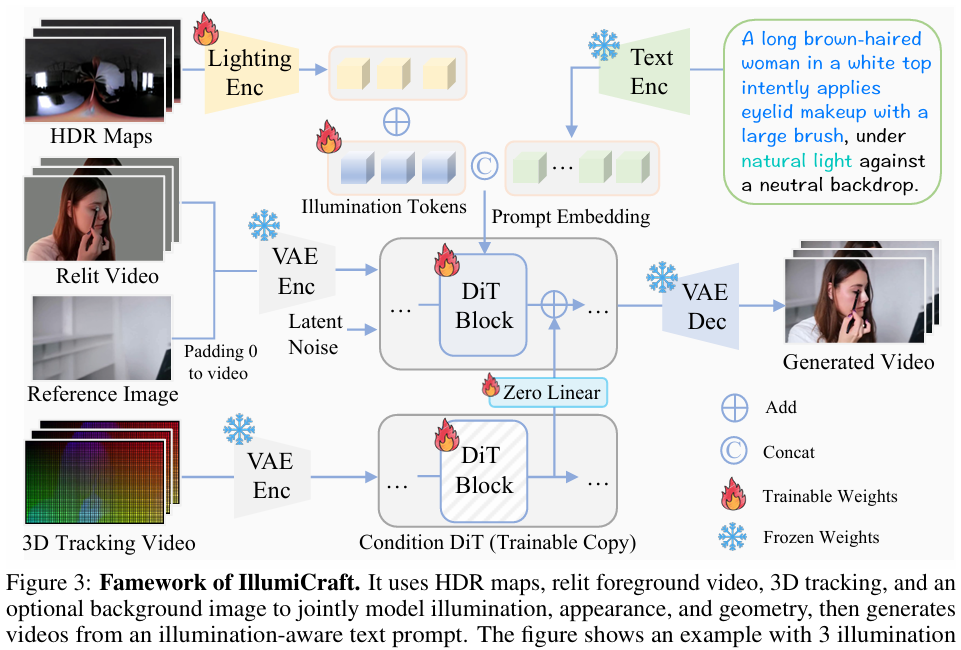
Latent Feature Extraction. 首先从背景视频提取第一帧作为参考图 $\mathcal{I}{\mathrm{ref}} \in \mathbf{R}^{H \times W \times 3}$ ,然后对其在时间轴上做零填充以得到参考视频 $\mathcal{V}{\mathrm{ref}} \in \mathbb{R}^{T \times H \times W \times 3}$
Inject Illumination Control. 为了从HDR maps中得到光照线索(illumination cues),首先利用一个compact MLP作为Encoder,将HDR视频 $\mathcal{V}{\mathrm{hdr}}$ 输入后得到一个特征矩阵 $\mathcal{X}{\mathrm{hdr}} \in \mathbb{R}^{N \times D}$ 。然后引入可学习的illumination embedding $\mathcal{X} \in \mathbb{R}^{N \times D}$ 进行更新: $\mathcal{X} \leftarrow \mathcal{X} + \mathcal{X}_{\mathrm{hdr}}$ 。此外,还将 $\mathcal{X}$ 和文本嵌入 $\mathbb{P} \in \mathbb{R}^{N \times D}$ 进行相加得到最终的光照控制条件 $\mathbb{P}’ \in \mathbb{R}^{(N+L) \times D}$
Integrate 3D Geometry Guidance. 扩展ControlNet且使用3D追踪视频 $\mathcal{V}_{\mathrm{geo}}$ 作为额外的控制信号。首先使用VAE得到一个隐变量,为了将控制信号诸如到DiT中,从DiT的预训练的32个transformer blocks中复制前4个blocks:将这四个块的输出放入一个零初始化的线性层中,然后将经过线性层后的输出add到DiT的主流特征图中。